From Data Challenges to Data Opportunities: Atlas' Journey with Singdata Lakehouse

Introduction: Revolutionizing Data Management at Atlas
Atlas, a leading provider of high-quality and cost-effective travel solutions, has recently upgraded its data platform with the adoption of Singdata Lakehouse. This strategic move has empowered Atlas to overcome critical challenges and achieve remarkable improvements in business efficiency and stability.
As a data-centric hub in the industry, Atlas collects and integrates data from various sources, including airlines, OTA platforms, and other partners, to provide data analysis and sharing services across its upstream and downstream ecosystem. However, the rapid growth of the company's business has led to a surge in data volume, diversifying business needs, and an increasing demand for real-time data updates, putting significant pressure on the data platform team.
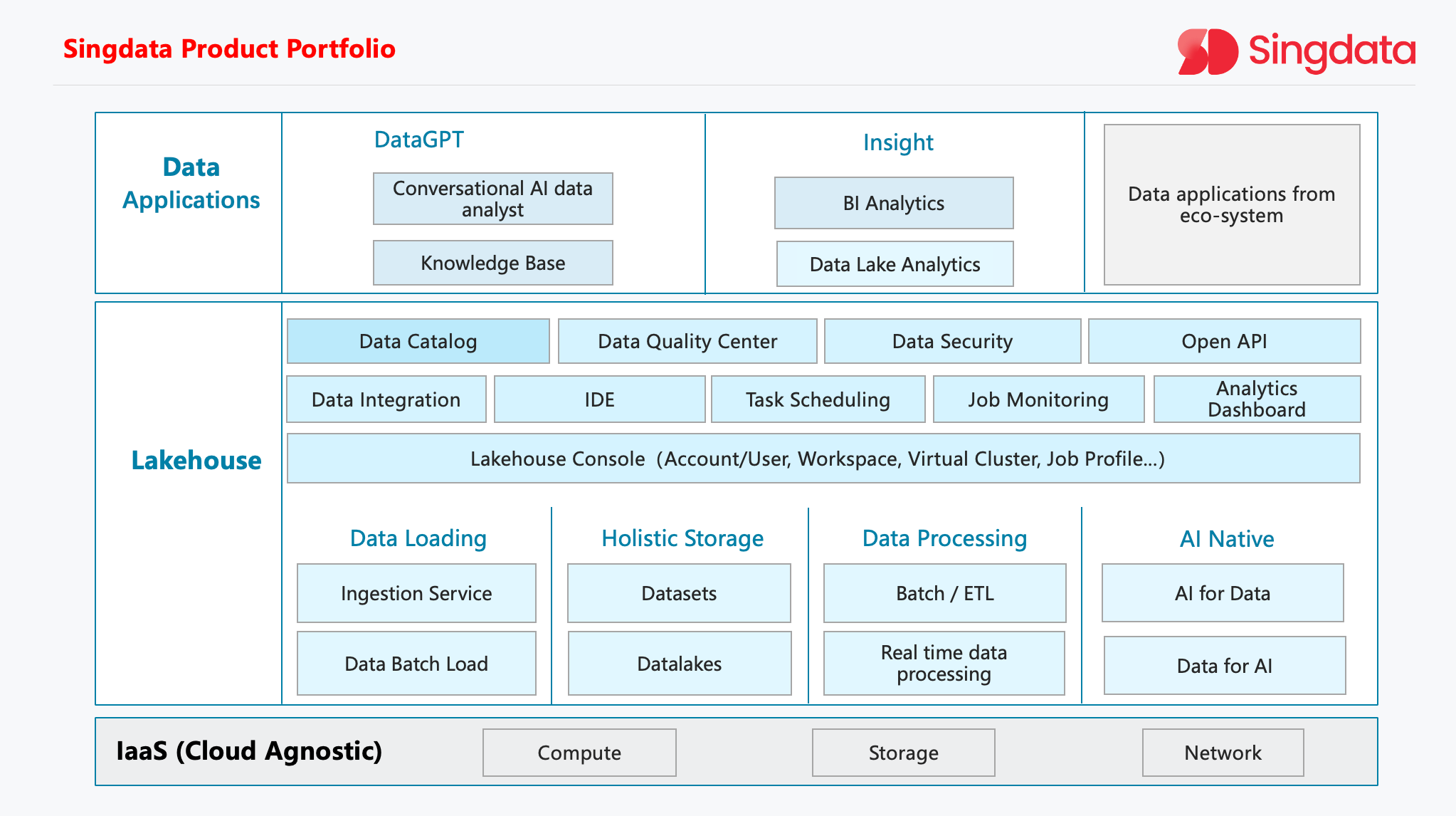
Recognizing the limitations of its previous data architecture, Atlas has embraced Singdata Lakehouse, a cutting-edge solution that seamlessly combines the best of data warehouses and data lakes, optimized the limitations of the previously purchased fixed-resource storage service, extending from storing 7 days of data to infinitely expandable and low-cost storage of 365 days of data. By leveraging Lakehouse, Atlas aims to streamline its data management processes, enhance data governance, and unlock new opportunities for business growth and innovation.
Atlas's Business and Data Challenges
Atlas's success in providing top-notch travel services has been accompanied by a rapid expansion of its business scale. As the company's operations grow, so does the volume of data it needs to handle. From airline ticketing data and booking platform orders to user behavior logs and third-party platform data, the scope of data collection has become increasingly broad. The peak value of data increments continues to reach new heights, with user search log data alone surpassing 600-700 million records per day.
BI ad-hoc query response experiences jitter and unstable query performance: The growth of enterprise data scale has led to Clickhouse's response time for multi-dimensional aggregation and statistical queries reaching over 60 seconds, failing to meet the query duration limit of BI application SuperSet. Actual test data shows that query response time increases linearly, affecting analytics user experience and possibly delaying decision-making processes. Optimizing Clickhouse's query engine and indexing mechanism can reduce query response time, improve query efficiency, and avoid query timeouts.
Atlas expects to further reduce cost consumption and improve production efficiency: The company hopes to further reduce data platform costs and improve overall operational efficiency. Cost issues include hardware and software procurement costs, maintenance, upgrades, and human resources. Currently, the data platform's operating costs account for a portion of the company's overall costs, and this proportion may further increase as the business scale grows. Introducing more efficient data storage and processing technologies and optimizing the data platform's architecture can reduce hardware and software costs and improve overall cost-effectiveness.
Moreover, the diversification of business needs has led to the evolution of airline travel analysis scenarios towards multi-dimensional and three-dimensional directions. The complexity of analysis scripts has gradually increased, posing additional challenges for the data platform.
Another critical aspect is the rising demand for real-time data updates. Some decision-making processes now require more timely and effective data, with update frequencies shifting from daily to multiple times a day, such as every few hours, every half hour, or even every 5 minutes or shorter intervals.
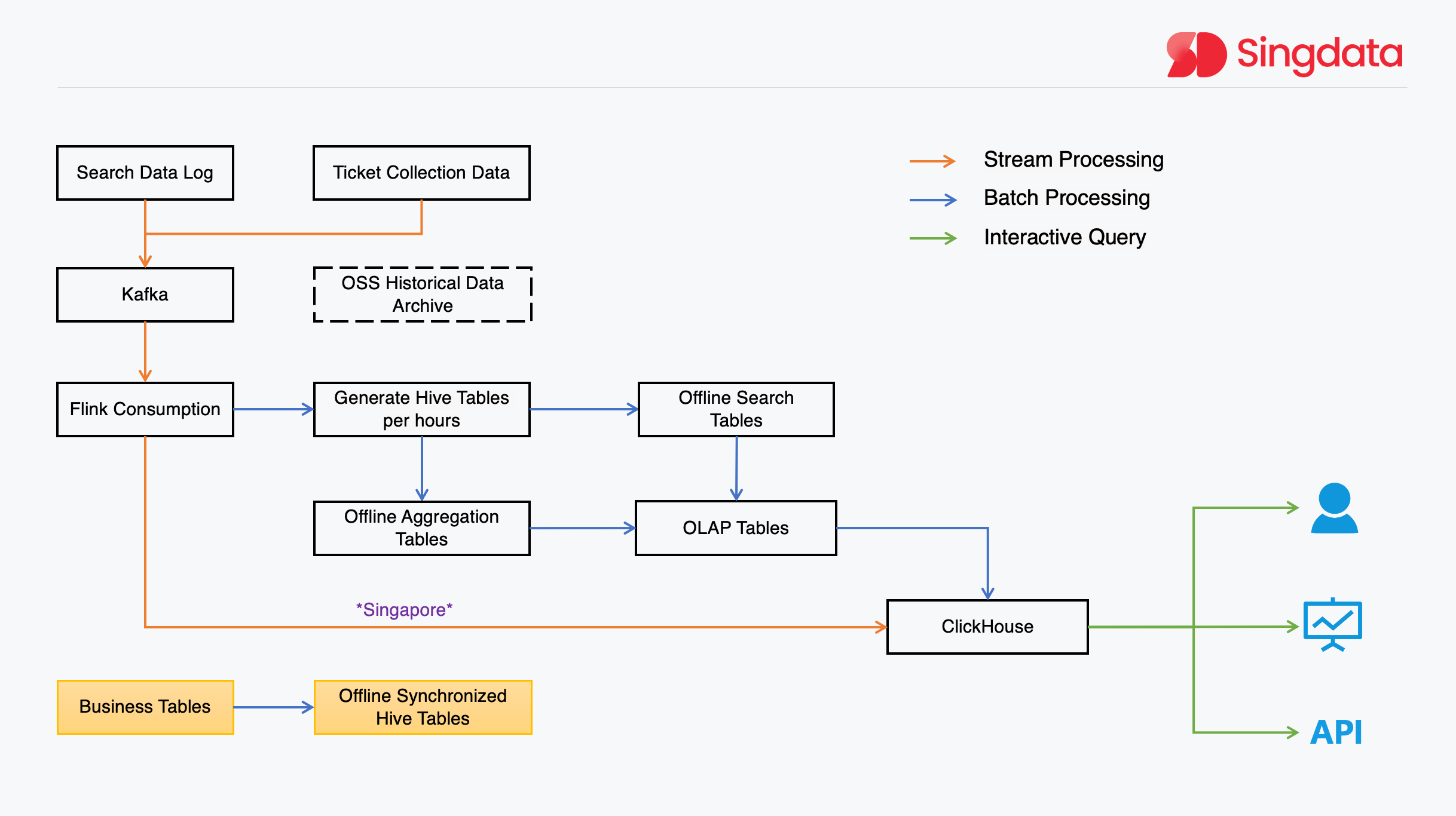
Limitations of Previous Data Architecture
Atlas's previous data architecture, although functional, had certain limitations that hindered its ability to keep pace with the evolving business requirements. The most prominent issue was the coexistence of offline and real-time pipelines, resulting in a typical Lambda architecture.
The data platform team had quickly built a real-time data processing pipeline based on Flink to address the pressing need for data timeliness. While this improvement temporarily met the business demands, it led to the coexistence of two separate pipelines for offline and real-time processing.
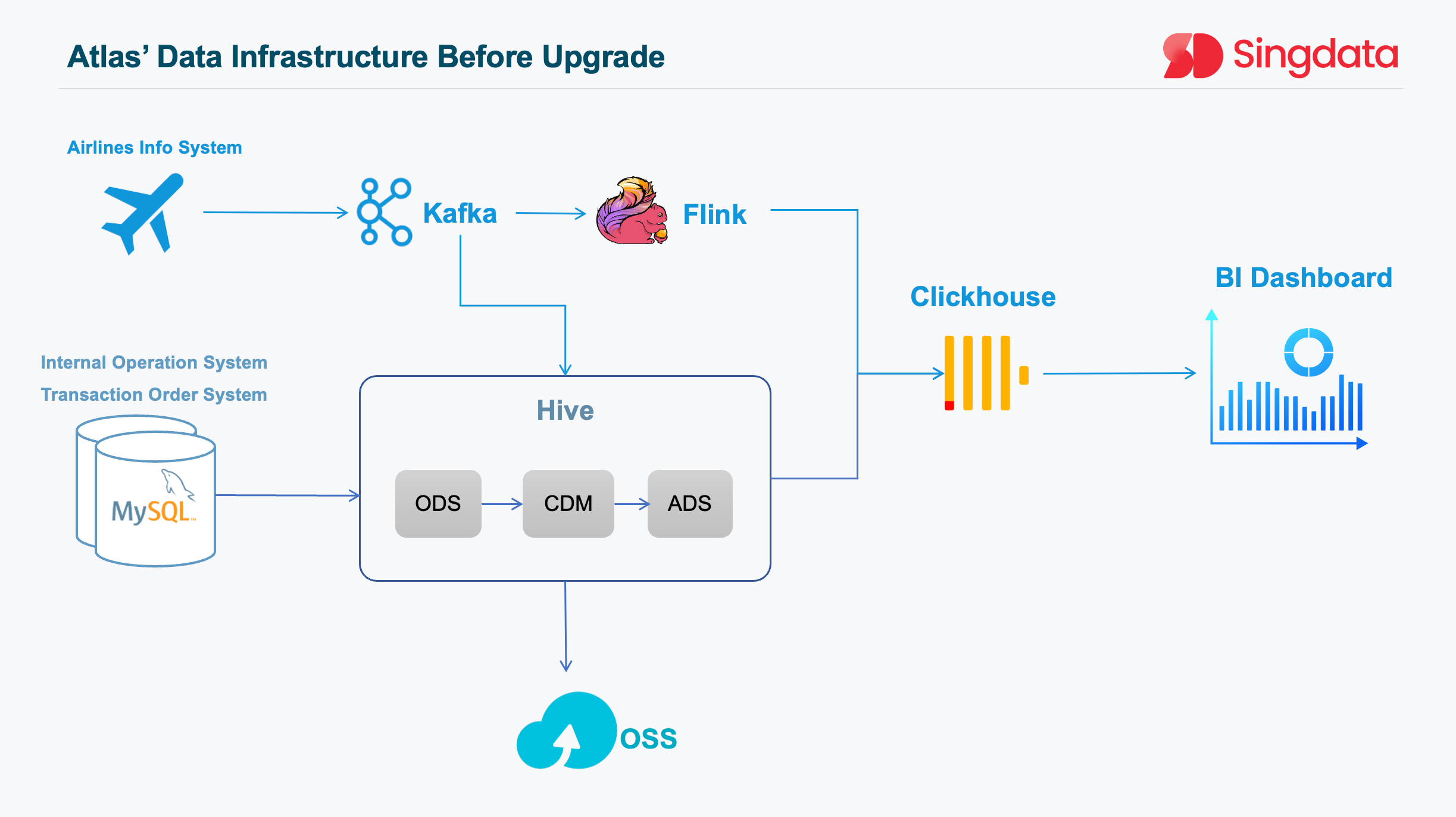
This architectural split posed several challenges:
Difficulty in unifying statistical calibers across the two pipelines
Complex data governance requirements that were hard to converge
Increased complexity in development, as teams had to maintain and update two distinct systems
Higher maintenance overhead, requiring more resources and effort to keep the system running smoothly
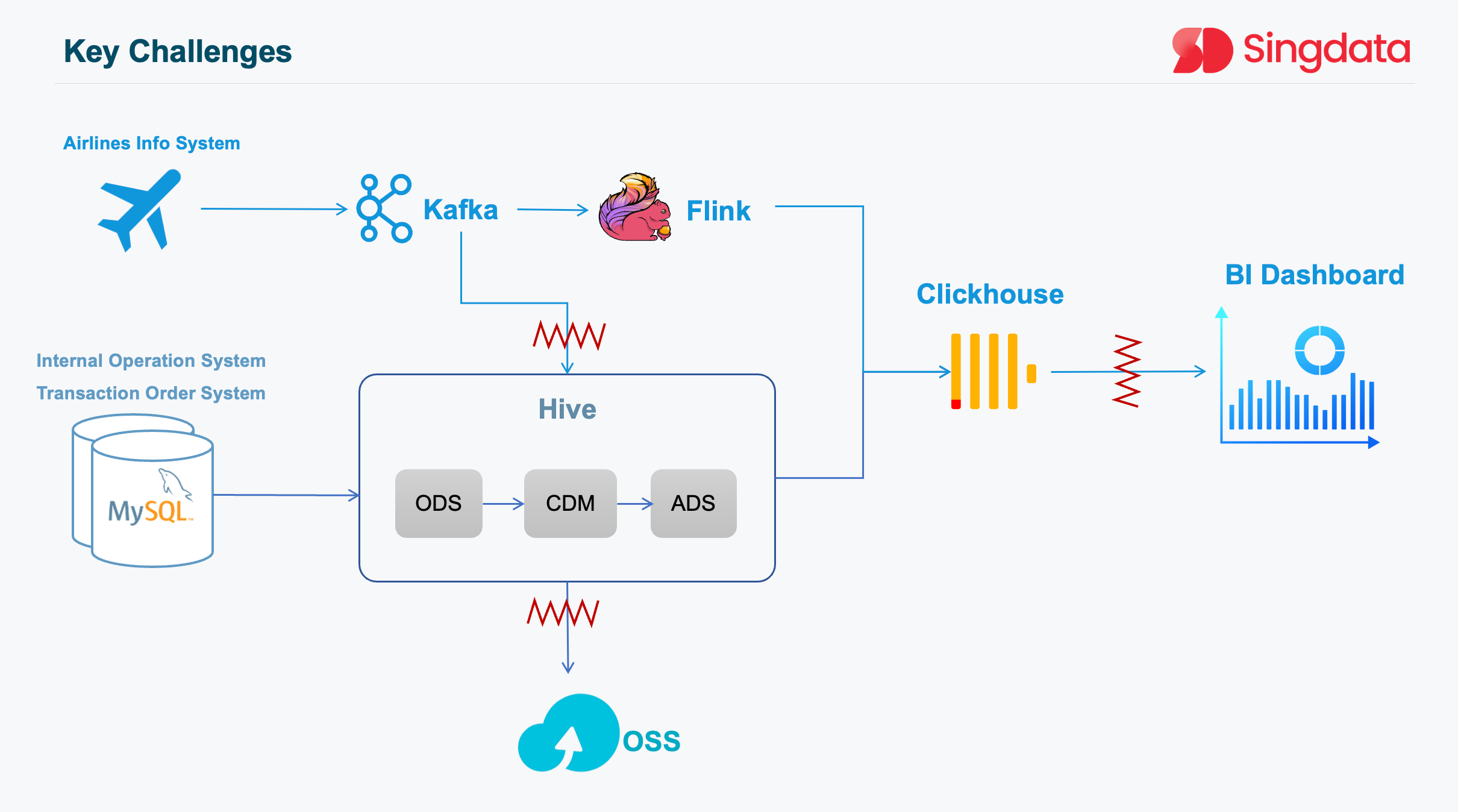
Call for Upgrades
As Atlas continued to thrive, two external factors accelerated the need for a data platform upgrade.
Firstly, the company's data volume began to expand at an accelerated pace alongside its business growth. The existing architecture struggled to keep up with the increasing data influx, necessitating a more scalable and efficient solution.
Secondly, the emergence of AI brought forth new opportunities for innovation. Atlas recognized the potential of leveraging AI to enhance its services and stay ahead of the competition. However, the current data platform lacked the necessary capabilities to fully support AI-driven initiatives.
These factors, combined with the limitations of the previous architecture, made it clear that an upgrade was not only necessary but also urgent.
Short-term Objectives for Data Platform Upgrade
To address the most pressing issues and lay the foundation for future growth, Atlas identified three key short-term objectives for the data platform upgrade:
Resolving interface timeout issues: The primary goal was to tackle the urgent problem of interface call timeouts, which were causing significant disruptions to the business.
Addressing data silos: Atlas aimed to break down the barriers between various data assets and create a more unified and cohesive data ecosystem.
Reducing maintenance costs and manual efforts: The company sought to streamline its data platform operations, minimizing the need for manual intervention and reducing overall maintenance costs.
By focusing on these short-term objectives, Atlas hoped to alleviate the immediate pain points and set the stage for more comprehensive enhancements in the future.
Initiatives for Evolution
Looking beyond the immediate challenges, Atlas recognized the importance of evolving its data platform to support long-term business growth and innovation. The company identified three key initiatives to drive this evolution:
Enhancing data intelligence and value discovery: As a data-driven company, Atlas sought to unlock the full potential of its data assets. By improving data intelligence capabilities and enabling more effective value discovery, the company aimed to gain deeper insights into customer preferences, market trends, and operational efficiency.
Developing real-time and intelligent data capabilities for AI-driven business: With the increasing adoption of AI technologies, Atlas recognized the need for a data platform that could support real-time and intelligent data processing. By developing these capabilities, the company could leverage AI to optimize its services, personalize customer experiences, and drive innovation.
Focusing on key elements: openness, scalability, and unification: To ensure the success of its data platform evolution, Atlas prioritized three key elements: openness, scalability, and unification. An open architecture would allow for seamless integration with external systems and data sources. Scalability would enable the platform to handle growing data volumes and complex workloads. Unification would break down data silos and create a single source of truth for the entire organization.
By aligning its initiatives with these key elements, Atlas aimed to create a future-proof data platform that could adapt to changing business needs and support the company's long-term success.
Selecting the Optimal Solution
To achieve its data platform evolution goals, Atlas conducted a thorough evaluation of various architectures and solutions.
Table 1: Solution Comparison between MPP and BSP/DAG/MapRuduce
Aspect | MPP | BSP/DAG/MapReduce |
|---|---|---|
Features | • Each single point is a relatively complete database, relying on Query's decomposition and result aggregation execution. • In-memory computation/Pipeline execution | • Divided into multiple Stages, with results persisted between Stages • Task-level resource scheduling |
Performance | First place, mainly fast | Second place, fast under large-scale front-end |
Cost | Medium-high | Medium-low |
Fault Tolerance | Second place, Query level, weak | First place, Task level, strong, mainly how to not crash |
Optimizer | Light, RBO, Plan Cache | Heavy, CBO |
Scheduling Strategy | • Operation-level concurrent control • Computation resource-driven • Local micro-scheduling | • Task-level concurrent control • Data-driven • Cluster-level resource allocation |
Data Model | Near PB | PB |
Representative Products | Starrocks/Doris/Clickhouse/SnowFlake/GreenPlum/Hologres | Hive/Spark/MaxCompute |
Corresponding VC | AP VC | GP VC |
After careful consideration, the company decided to adopt the Lakehouse architecture offered by Singdata.
The selection process involved several key steps:
Evaluating Lakehouse architecture and comparing with alternatives: Atlas's technical team assessed the capabilities of the Lakehouse architecture and compared it with other options, such as traditional data warehouses and data lakes. The team found that Lakehouse offered the best combination of performance, scalability, and flexibility.
Designing data integration for Atlas's data system: Singdata's solution team worked closely with Atlas to design a data integration strategy that would seamlessly incorporate the company's existing data assets into the new Lakehouse environment. This involved leveraging Singdata's powerful data integration tools and expertise to ensure a smooth transition.
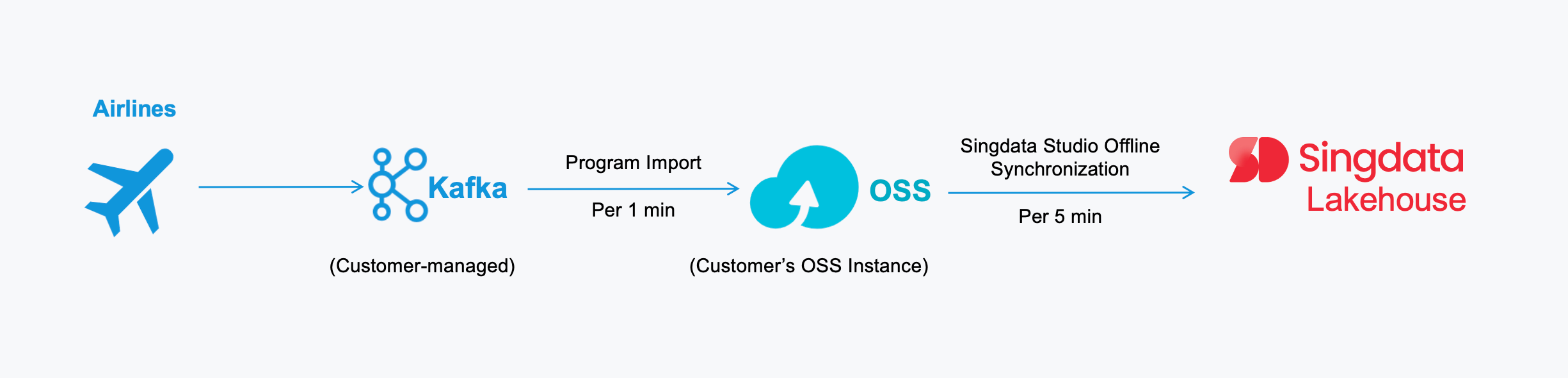
Since the upstream data sources of ticket data and search logs are all uniformly summarized to Kafka, a program is developed to read data from Kafka and write one file to OSS every minute. Then, Sindata Studio's OSS data synchronization function is used to write the data to Lakehouse. In this process, the ODS layer retains the original JSON data, and the DWD layer completes the transformation of the JSON file format and subsequent aggregation. This solution meets the real-time scenario requirements of data freshness within 10 minutes from the source Kafka to the final data platform consumption end, and gradually approaches 5 minutes. Most importantly, the cost is far less than a resident real-time processing task. The interactive analysis scenario of multi-dimensional aggregation and associative query performance of 800 million data can meet the application-side requirements. Moreover, since data transmission is within OSS, avoiding "public network" network transmission, it also reduces overall storage and network transmission costs.
Validating performance of query engines: To ensure that the Lakehouse architecture could meet Atlas's performance requirements, the technical team conducted rigorous testing and validation of the query engines. The tests involved loading data from OSS into Singdata Lakehouse, preprocessing it using the General Purpose Virtual Cluster, and then querying the resulting tables using the Analytical Purpose Virtual Cluster. The results demonstrated significant improvements in query performance and stability.
In Atlas' data system, the collection, storage, and transmission of original data are all performed using the JSON format. Singdata Lakehouse's from_json function is used for one-time field flattening. According to actual production conditions, data is written to OSS in JSON format via Kafka, and offline synchronized to Lakehouse at 5-minute intervals. After data landing, JSON data splitting and field flattening are directly completed through SQL Volume Load. After data parsing, the link SQL performs association, aggregation, deduplication, and other processing calculations. The latency from the data application side's Ad Hoc, BI query, and API calls meets the requirement of 10 minutes to 5 minutes.
By selecting Singdata Lakehouse as its optimal solution, Atlas was confident in its ability to overcome its data challenges and drive business value through enhanced data management and analytics capabilities.
Data Migration and Implementation
With the solution selected, Atlas swiftly initiated the data migration process. The entire migration took approximately half a month, thanks to the efficient collaboration between Atlas's team and Singdata's delivery team.
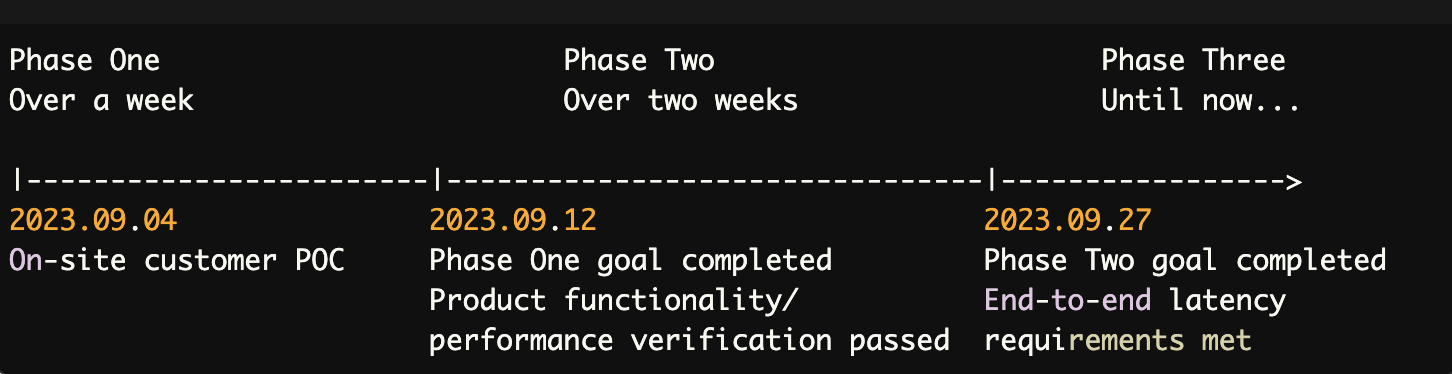
Throughout the migration, several key steps were undertaken to ensure a smooth and successful transition:
Rebuilding the data warehouse system: Atlas redefined its data business objectives, starting from data convergence governance, data quality management, and collection optimization. The team then designed and implemented a comprehensive data warehouse system aligned with these objectives.
Integrating real-time and offline data streams: By unifying the real-time and offline architectures, Atlas achieved a significant performance boost in data processing. This integration enhanced the timeliness of data services, upgrading the existing data reporting service from T+1 to minute-level updates.
Optimizing SaaS services and costs: The new platform adopted a usage-based billing model, calculating costs based on the actual consumption of computing, storage, and network resources. This optimization reduced overall costs by 50% and lowered operation and maintenance expenses by more than 70%.
Designing high-concurrency, low-latency compute clusters: Atlas implemented a high-performance compute cluster architecture to support the data product team's SaaS custom reporting capabilities. This enhancement expanded the dimensions of customer business data analysis and insights, enabling the delivery of unique, customized reports for each client.
By focusing on these critical implementation steps, Atlas successfully migrated its data assets to the Singdata Lakehouse platform, laying the foundation for improved data management, analytics, and business value generation.
Results and Business Value Post-Upgrade
Following the successful implementation of Singdata Lakehouse, Atlas has witnessed remarkable improvements in its data platform performance and business value delivery.
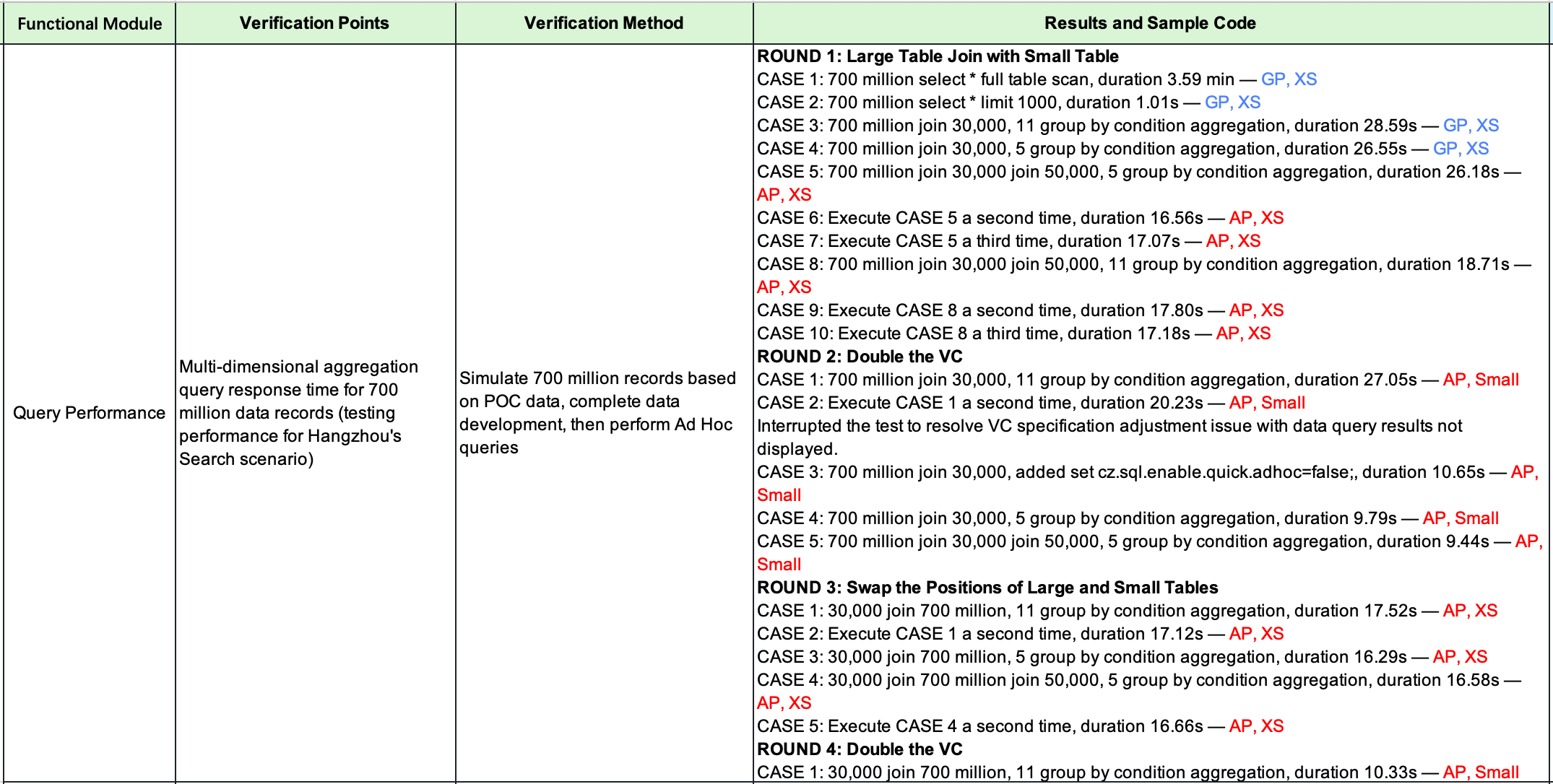
From a qualitative perspective, the upgraded platform has significantly enhanced data processing efficiency and stability. The "unlimited" storage capacity of the Lakehouse architecture ensures that Atlas can seamlessly handle the ever-growing volume of data generated by its expanding business.
Regarding the query performance of the computing engine, we selected a typical scenario to perform verification tests on the engine. After loading the test data from OSS to Singdata Lakehouse, it is preprocessed in the General Purpose Virtual Cluster, and then the result table is directly queried by the business system in the Analytical Purpose Virtual Cluster of Singdata. Here are some performance verification results. First, we verified the query situation of over 700 million data. Under the same or lower resource specifications as the original platform, the engine can return data within 10 seconds. For this, the platform team conducted multiple rounds of queries of various types. Without performance tuning, it can basically meet the linear scaling requirements. By expanding the computing resource specifications, the computing consumption time can be proportionally reduced accordingly, thus obtaining performance indicators that are very satisfactory to both the technology team and the business team.
Continuing with data-level optimization, the final 700 million data with 5 keys took about 3 minutes for window processing, which is even faster than the 200 million data case of similar real-time data warehouse products investigated. Satisfyingly, during the entire query and computation process, Singdata achieved pay-as-you-go for resources and automatic elastic scaling of computing resources. For this, the platform team also conducted specialized verification on virtual compute clusters. From the results, computing resources are basically booted up in milliseconds and released within minutes, ensuring the minimization of computing costs.
Moreover, the 100% serveless (fully managed) architecture of the Singdata Lakehouse has dramatically reduced the burden on Atlas's internal teams. The platform is essentially maintenance-free, allowing the company to focus its resources on more strategic initiatives and innovation.
The streamlined data management processes have also led to a notable reduction in internal friction costs. By breaking down data silos and enabling smoother collaboration across departments, Atlas has improved overall operational efficiency and decision-making agility.
Perhaps most importantly, the upgraded data platform has positioned Atlas to support its ambitious business expansion plans. With a scalable, flexible, and AI-ready foundation in place, the company is well-equipped to pursue new growth opportunities and deliver enhanced value to its customers.
Finally, the migration to Singdata Lakehouse has significantly improved system stability. Atlas no longer faces the interface timeout issues that previously plagued its operations, ensuring a more reliable and consistent user experience.
Conclusion
Atlas's journey of upgrading its data platform with Singdata Lakehouse has been a resounding success. By addressing its immediate challenges and laying the foundation for future growth, the company has positioned itself as a leader in data-driven innovation within the travel industry.
Looking ahead, Atlas is excited about the possibilities that its enhanced data capabilities will unleash. With a powerful, scalable, and AI-ready platform at its disposal, the company is poised to deliver even greater value to its customers and stakeholders.
As the travel industry continues to evolve and new challenges emerge, Atlas is confident that its partnership with Singdata and the Lakehouse architecture will provide the agility and insights needed to stay ahead of the curve. The future is bright for Atlas, and the company looks forward to leveraging its data assets to drive success for years to come.
