Single-Engine Lakehouse: What You Need to Know

A Single-Engine Lakehouse represents a modern data architecture that merges the benefits of data lakes and data warehouses. This architecture simplifies data management by using a single engine to handle diverse workloads. Understanding this architecture is crucial for modern data management. It addresses common issues like high costs and complex data governance. The Single-Engine Lakehouse offers a streamlined, cost-effective solution that supports efficient data operations and scalability.
Understanding the Single-Engine Lakehouse
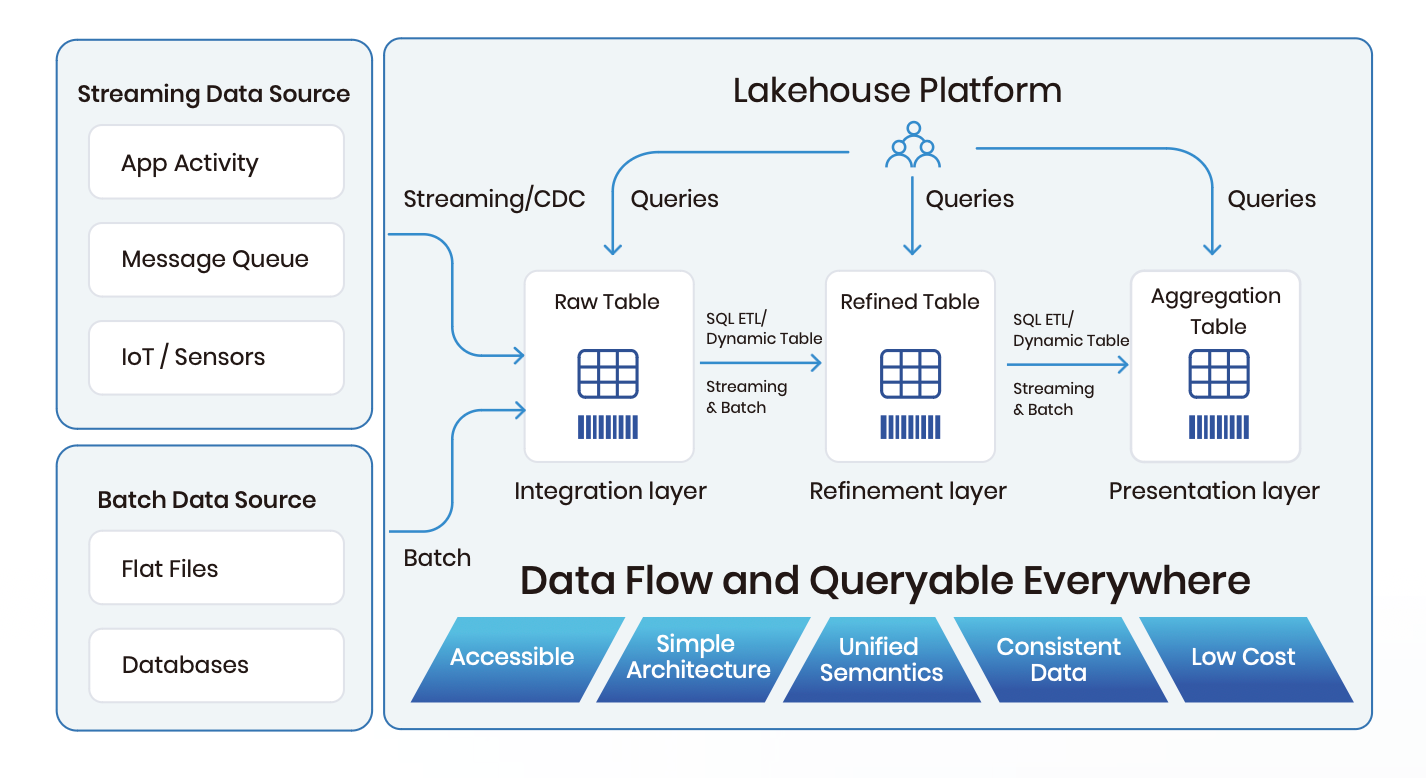
Definition and Core Principles
What is a Single-Engine Lakehouse?
A Single-Engine Lakehouse represents a unified data platform. This platform merges the functionalities of data lakes and data warehouses. The architecture uses a single engine to handle diverse workloads. This approach simplifies data management and enhances efficiency.
Key Principles Behind the Architecture
The core principles of a Single-Engine Lakehouse include:
Unified Data Processing: The architecture supports batch, streaming, and interactive queries within one engine.
Simplified Data Governance: Centralized governance ensures consistent data policies.
Cost Efficiency: The single-engine approach reduces infrastructure costs by optimizing resource utilization.
Evolution of Data Architectures
From Data Warehouses to Data Lakes
Data warehouses emerged first, providing structured data storage for business intelligence (BI) applications. These systems excelled in handling structured data but struggled with unstructured data. Data lakes then appeared to address this limitation. They allowed storage of both structured and unstructured data. However, data lakes lacked the performance and governance features of data warehouses.
The Emergence of the Lakehouse
The Single-Engine Lakehouse emerged to combine the strengths of both data lakes and data warehouses. This architecture integrates the scalability of data lakes with the performance and reliability of data warehouses. Companies like Databricks and IBM have adopted this approach to enhance their data platforms.
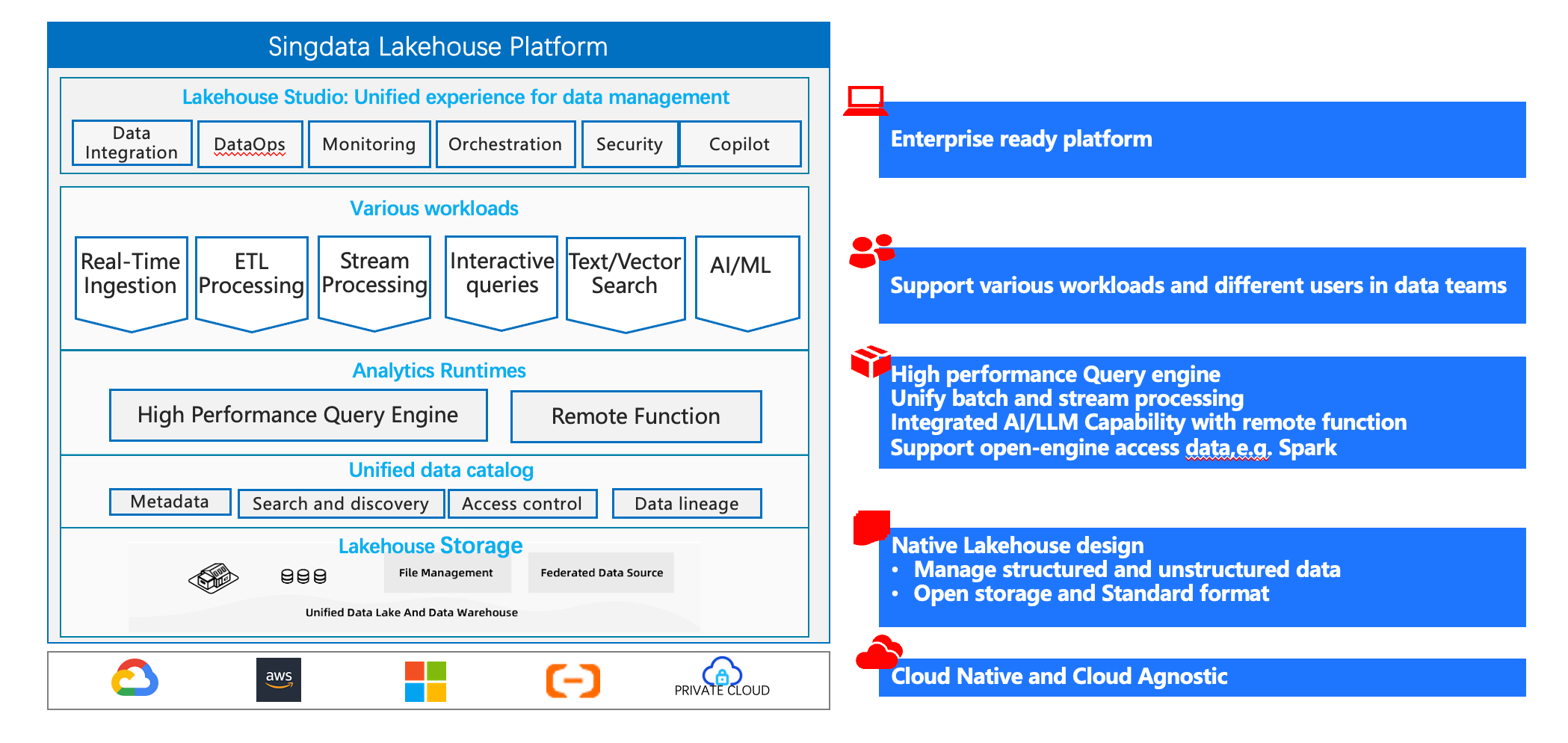
Key Components
Storage Layer
The storage layer in a Single-Engine Lakehouse handles vast amounts of data. This layer supports both structured and unstructured data. Technologies like Delta Lake and Apache Iceberg enable efficient data storage and retrieval.
Compute Engine
The compute engine processes data queries and transformations. It supports real-time analytics, batch processing, and interactive queries. The Lakehouse Engine, an open-source Spark framework, exemplifies a robust compute engine.
Metadata Management
Metadata management ensures data consistency and governance. This component tracks data lineage and schema evolution. Effective metadata management simplifies data operations and enhances data quality.
Benefits of a Single-Engine Lakehouse
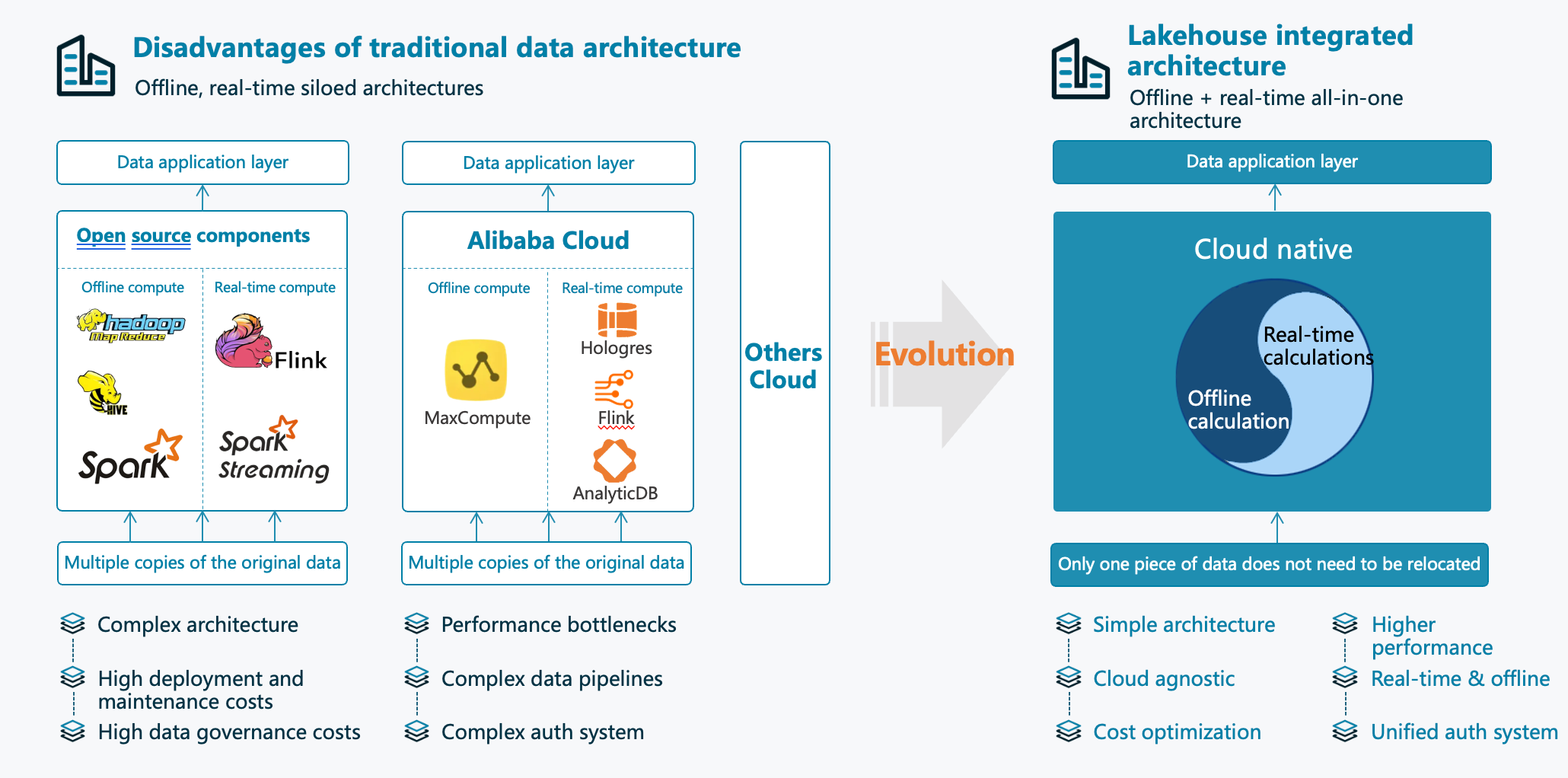
Unified Data Management
Simplified Data Operations
A Single-Engine Lakehouse streamlines data operations. The architecture eliminates the need for multiple data processing engines. This unified approach reduces complexity in managing data workflows. Data engineers can handle batch, streaming, and interactive queries with one engine. This simplification leads to more efficient data operations.
Consistent Data Governance
Consistent data governance is crucial for maintaining data quality. A Single-Engine Lakehouse centralizes governance policies. This centralization ensures uniform data management practices across the organization. Data lineage and schema evolution are easier to track. This consistency enhances data reliability and compliance.
Performance and Scalability
Efficient Query Processing
Efficient query processing is a hallmark of the Single-Engine Lakehouse. The architecture supports real-time analytics and batch processing. This capability allows for quick data retrieval and analysis. Technologies like the Lakehouse Engine optimize query performance. Users experience faster response times for their data queries.
Scalability Across Large Datasets
Scalability is essential for handling large datasets. A Single-Engine Lakehouse scales efficiently with growing data volumes. The architecture leverages distributed computing frameworks. This scalability supports the linear growth of data analytics without bottlenecks. IoT companies benefit significantly from this capability.
Cost Efficiency
Reduced Infrastructure Costs
Reduced infrastructure costs are a significant advantage of a Single-Engine Lakehouse. The architecture converges batch and real-time analytics into one engine. This convergence lowers the total cost of ownership (TCO) by 50%. Organizations save on hardware and software expenses. This cost efficiency makes the lakehouse an attractive option.
Optimized Resource Utilization
Optimized resource utilization is another benefit of a Single-Engine Lakehouse. The architecture balances data freshness, query performance, and cost control. Resources are allocated based on workload demands. This optimization ensures that no resources are wasted. Organizations achieve better performance at a lower cost.
The Single-Engine Lakehouse architecture merges data lakes and data warehouses. This architecture simplifies data management and enhances efficiency. The key components include a unified data processing engine, centralized governance, and optimized resource utilization. The benefits include reduced infrastructure costs and improved scalability for large datasets.
The Single-Engine Lakehouse offers a streamlined solution for modern data management. Organizations can achieve better performance and cost savings. The architecture supports IoT companies' linear growth without bottlenecks. Further exploration and adoption of the Single-Engine Lakehouse will drive innovation in data infrastructure.
