How Kuaishou cut data freshness from T+1 to minutes, while spending less on compute

Summary
Kuaishou processes hundreds of billions of records a day. Their batch pipelines worked, but the data was always a day old by the time anyone could use it. Making it faster meant either spending a lot more money or running two separate systems (batch + streaming) with all the overhead that brings. This article walks through how Kuaishou's data platform team and Singdata built and validated a new approach -- Generic Incremental Computing (GIC) -- on real production workloads.
Background
Kuaishou at a glance
Kuaishou is one of China's largest short-video platforms. The data platform team runs batch processing across exabytes of data on clusters with millions of cores. Content recommendations, ad targeting, business reporting -- it all runs through these pipelines.
The problems they were trying to solve
Their batch architecture had three pain points that kept getting worse as the business grew.
First, stale data. Batch jobs ran on a T+1 cycle. By the time results were ready, the data was already a day old. For use cases like A/B testing and ad model training, that delay killed a lot of the value.
Second, wasteful recomputation. Even if only 1% of the source data changed, batch jobs reprocessed 100% of the historical data every run. As data volumes grew, costs kept climbing.
Third, two systems to maintain. The common workaround for latency was adding Flink streaming pipelines alongside batch -- the classic Lambda architecture. That meant two codebases, two sets of operational tooling, and double the maintenance work.
Why they chose incremental computing
The team evaluated several near real-time approaches before landing on incremental computing. The core idea: when upstream data changes, only recompute the parts that are actually affected, then merge the results with the previous output. This sidesteps the Lambda problem entirely and moves toward a single unified system (Kappa architecture).
Kuaishou's data platform team and Singdata formed a joint project group to build and test a production-grade version they call Generic Incremental Computing, or GIC.
What they set out to prove
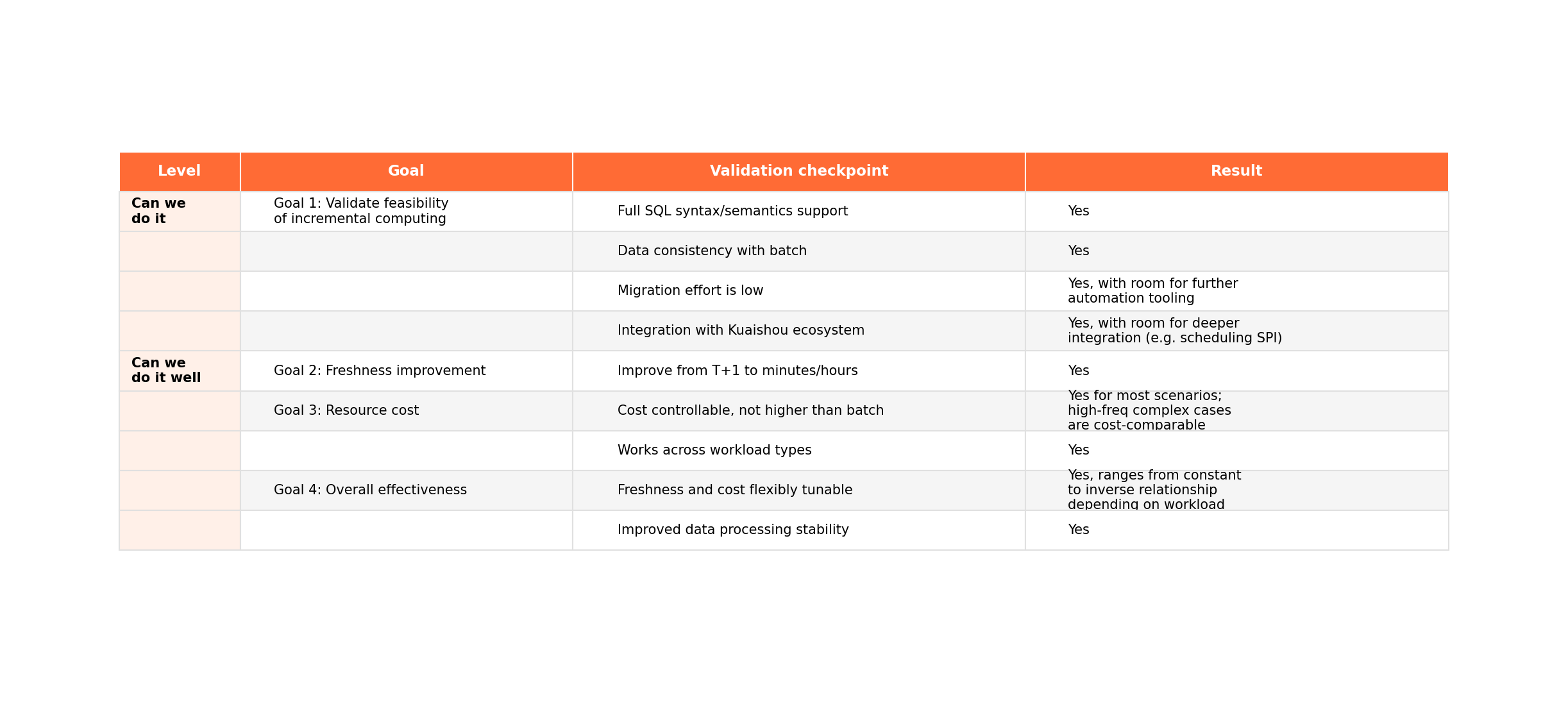
The team framed the evaluation around two questions: "Can we actually do this?" and "Can we do it well?"
On the feasibility side: does incremental computing work for Kuaishou's real-world SQL workloads, including complex joins, window functions, and UDFs? Does the data match batch results? Can engineers migrate existing pipelines without rewriting everything?
On the performance side: how much faster is it? What does it cost compared to batch? Can you tune the latency-cost tradeoff on the fly?
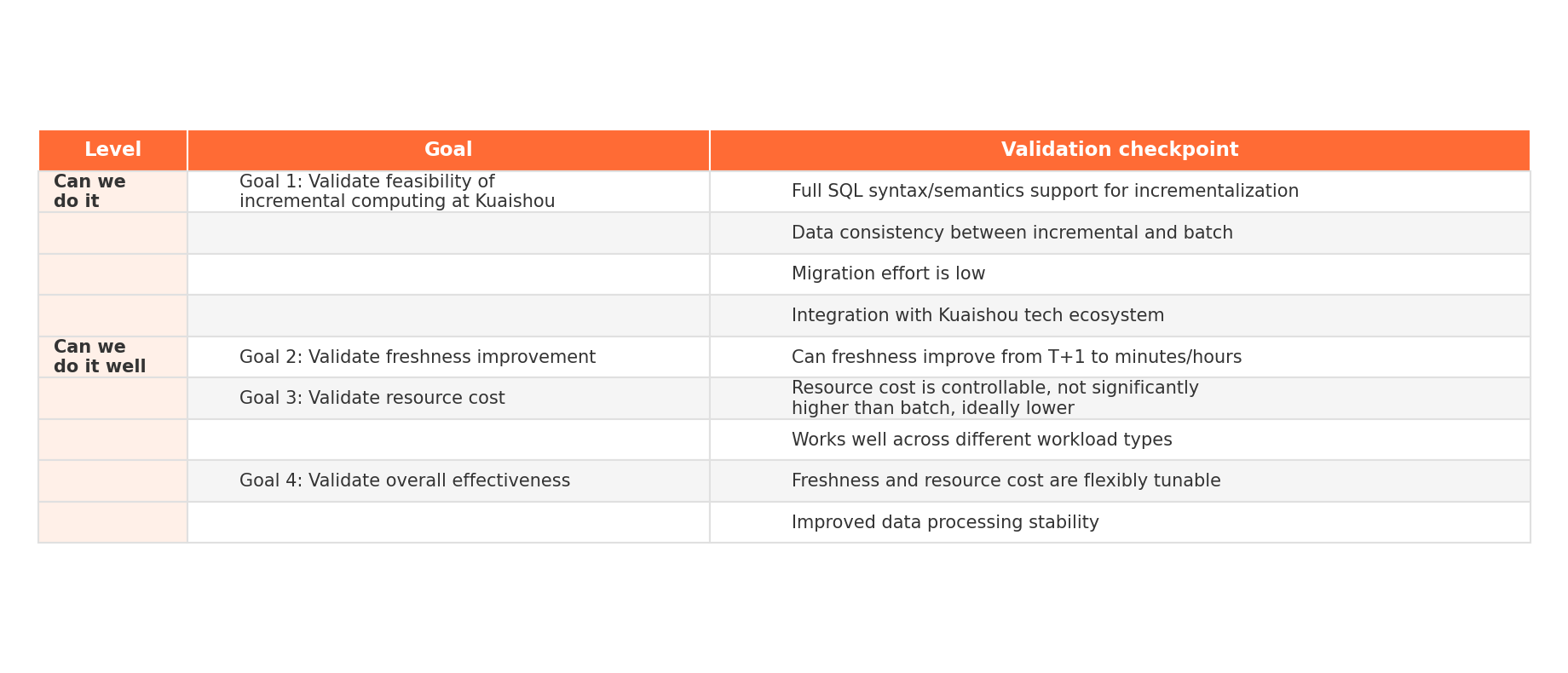
Test design
They picked three production pipelines of increasing complexity:
- Simple: tens of GB per day, basic transformations, typical of most workloads
- Medium: several TB per day, simple computations but much more data
- Complex: 10+ source tables (three over 10 TB each), dozens of joins, window functions, UDFs, four layers of processing -- one of the hardest pipelines to incrementalize at Kuaishou
The logic was simple: if the complex pipeline works, everything else should be fine.
Results
The numbers
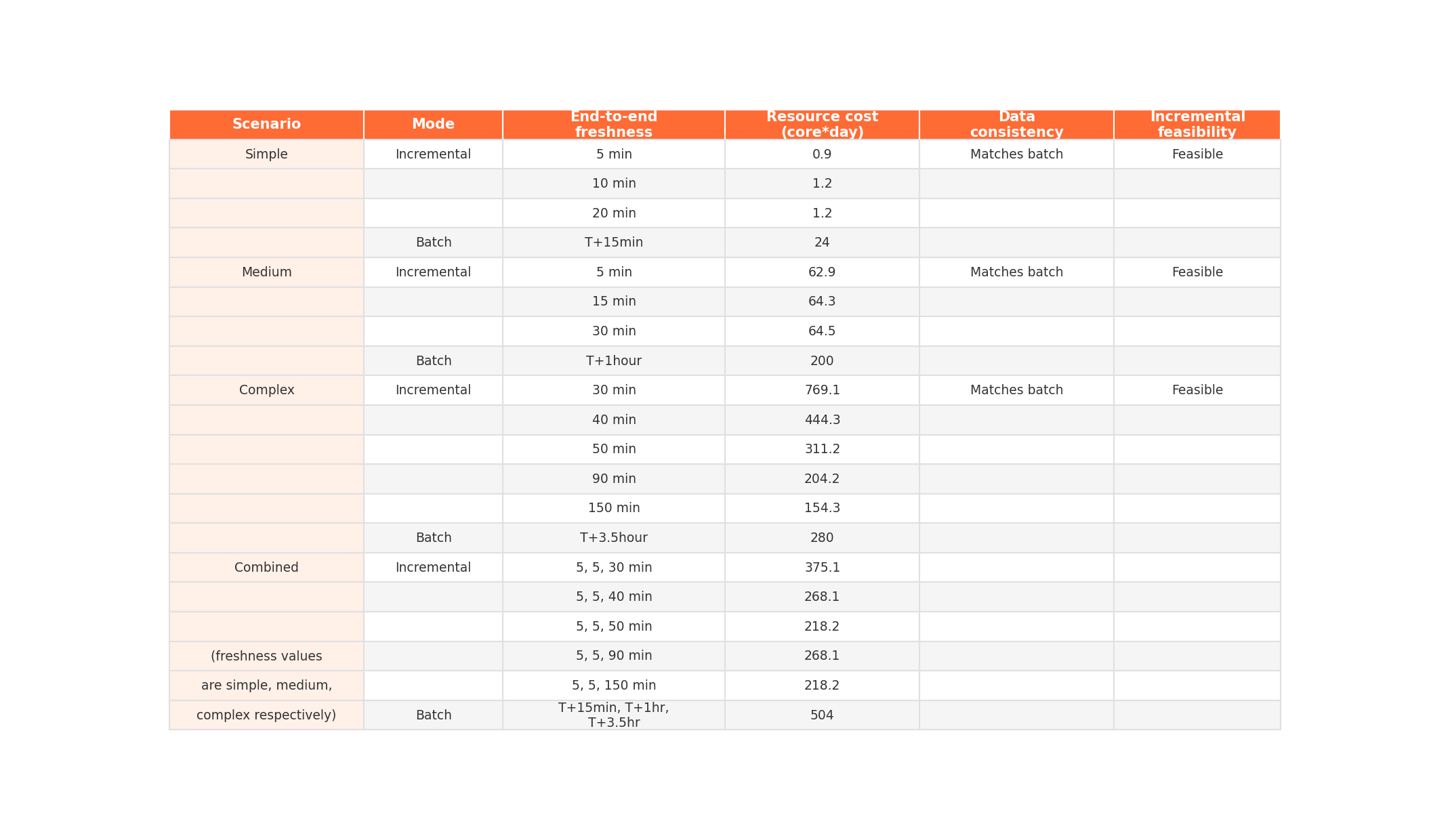
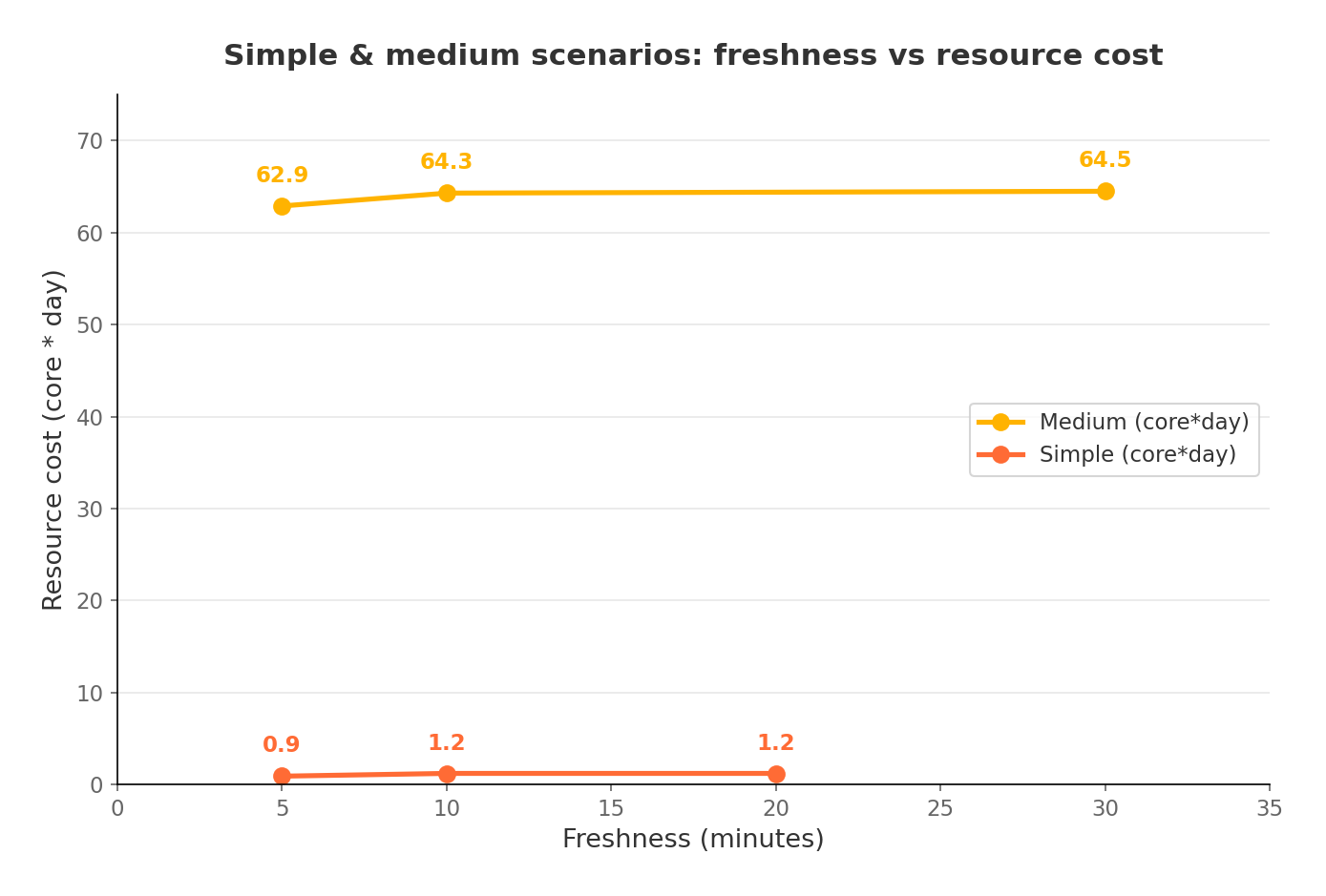
For simple and medium workloads, incremental computing hit 5-minute data freshness (and could go lower). Resource consumption was less than 1/20th of batch for the simple case and under 1/3rd for the medium case.
For the complex workload, the fastest achievable freshness was about 30 minutes (across a 4-layer pipeline fed by three large tables). At that aggressive cadence, cumulative resource usage was higher than a single batch run. But at 50-minute intervals the costs were roughly even, and at 90 minutes or above, incremental computing was cheaper.
When all three workloads ran together -- simulating a real mixed environment -- the breakeven point landed at roughly 5/5/40 minutes freshness for simple/medium/complex respectively. Push the complex pipeline to a more relaxed cadence and overall costs drop well below batch.
Freshness and resource spend are independently tunable per pipeline.
Feasibility: yes, it works
Every SQL construct they threw at it -- joins, window functions, aggregations, UDFs (deterministic ones) -- ran incrementally. Nothing had to fall back to full recomputation.
Incremental results matched batch results exactly.
Migration was easy. The SQL syntax and processing logic are identical to batch. Most of the work was copy-paste, with minor scheduling config changes. No query rewrites.
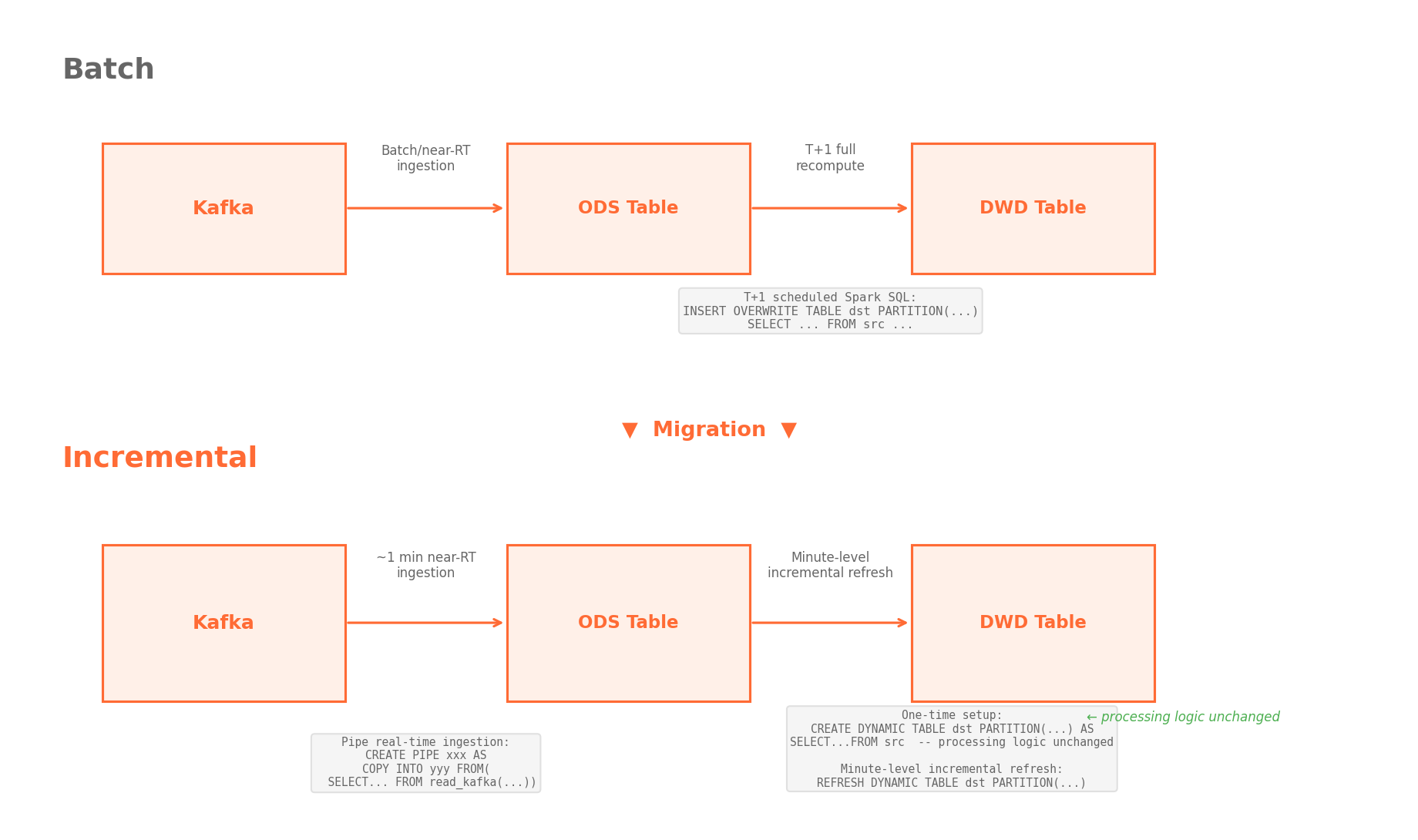
The system also integrated cleanly into Kuaishou's existing infrastructure. Downstream consumers didn't need changes.
Performance: tunable latency-cost tradeoff
The relationship between refresh frequency and resource cost depends on the workload.
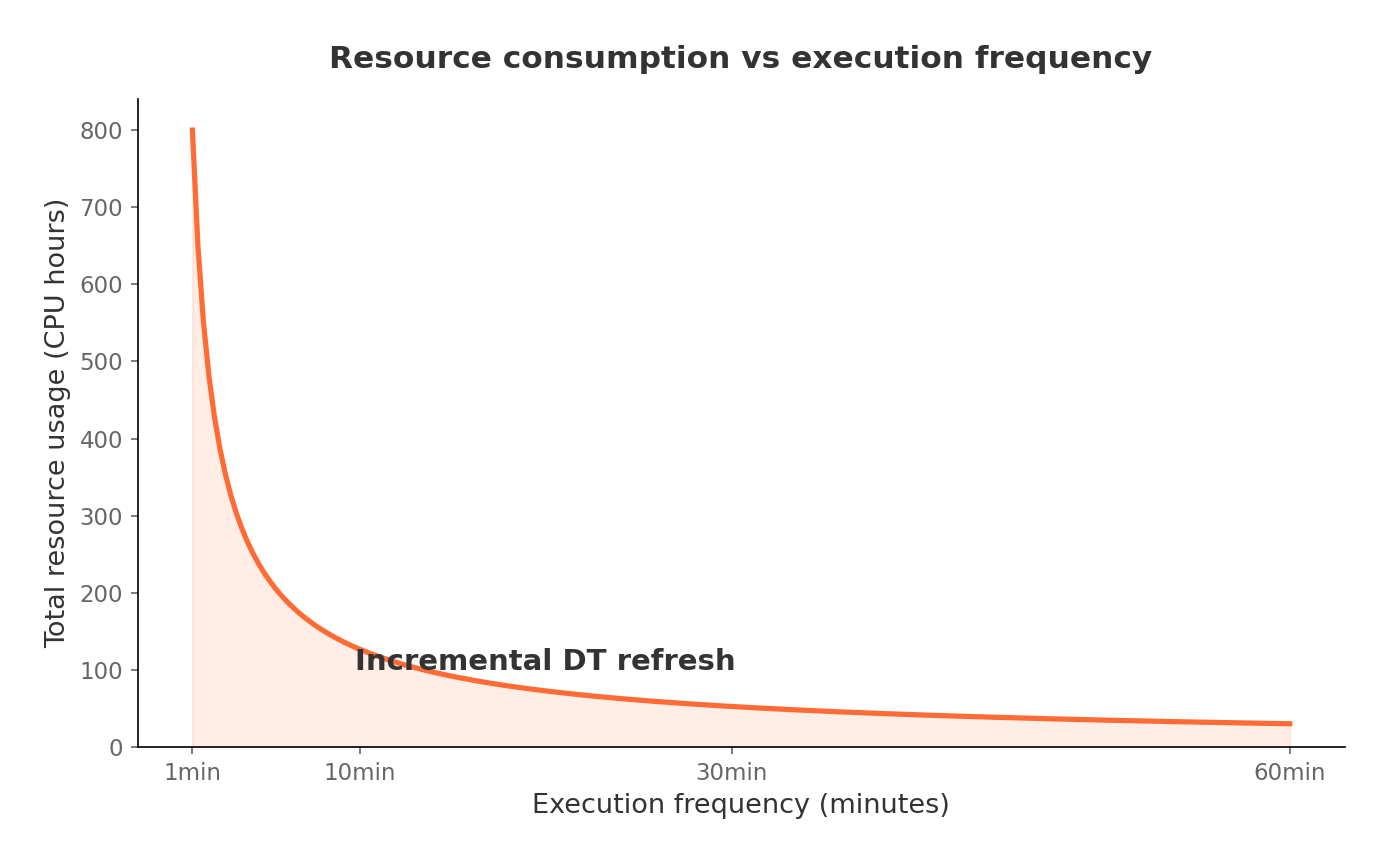
For append-heavy, simple workloads, cost stays roughly flat regardless of how often you refresh. The per-run overhead is small and so is the incremental data volume.
For complex workloads with heavy historical data involvement (joins against large dimension tables, for example), cost scales roughly inversely with the refresh interval. Refresh every 30 minutes and you pay more per day. Refresh every 90 minutes and you pay less than batch.
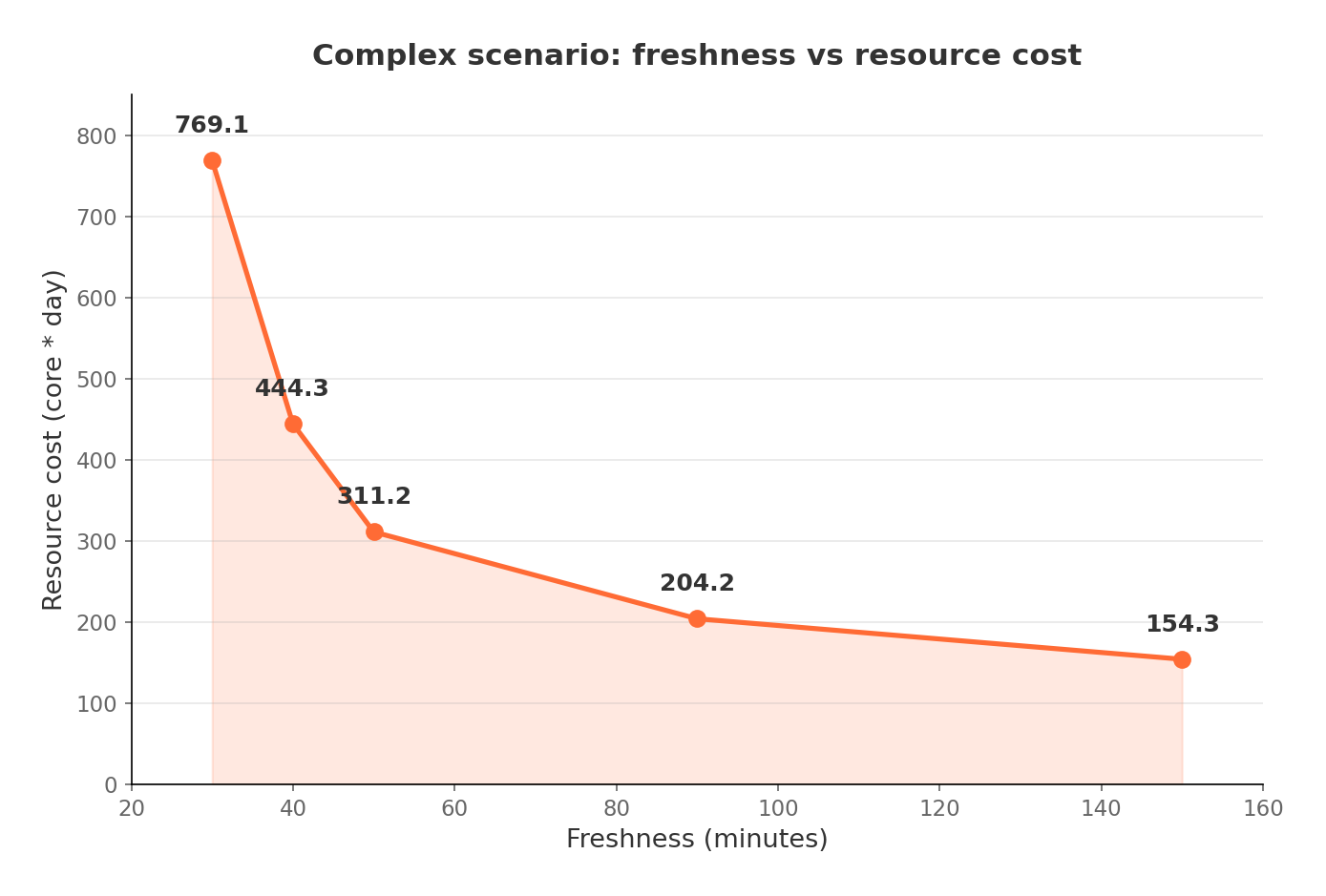
This gives teams a practical lever: crank up freshness during promotional events, dial it back during normal operations to save money.
Stability improvements
There's a less obvious but operationally important benefit. Batch pipelines at Kuaishou have strict SLA deadlines -- miss the window and downstream reporting breaks (internally called "breaking the line"). Batch is vulnerable because each run processes a full day's data in one shot, and the processing window is short: typically a few hours starting after midnight.
Incremental computing spreads the work across the entire day. Each run processes a small slice of data, finishes quickly, and is cheap to retry. The effective processing window stretches to over 24 hours instead of a few. Failures get caught and recovered long before any SLA is at risk.
How it works under the hood
Four factors determine how much an incremental run actually costs:
-
Query complexity. More joins, window functions, and aggregations mean more work per run. Outer joins are especially expensive because updates to one side can trigger retractions of previously computed results.
-
Change type. Append-only changes are cheap (new rows rarely need to touch historical data). Updates and deletes are more expensive because they can cascade through downstream computations.
-
Change volume. Processing 10,000 new rows per cycle is different from processing 1,000,000.
-
Refresh frequency. More frequent runs mean more fixed overhead (scheduling, I/O setup, result writing).
Traditional rule-based incremental engines decide at query definition time whether a query can be incrementalized, then lock in a fixed execution plan. This accounts for factor #1 partially but ignores #2 through #4. The result is unpredictable performance: some runs are fast and cheap, others are slower than batch would have been, and operators end up manually tuning the system all the time.
GIC uses a cost-based query engine instead. Before each refresh, it evaluates all four factors against a cost model and picks the best execution strategy -- sometimes fully incremental, sometimes partially, sometimes full recomputation for specific operators. This happens automatically, so engineers focus on business logic rather than system tuning.
What comes next
Kuaishou is moving to broader adoption. Two pilot migrations are planned for 2026: one is an advertising pipeline where minute-level freshness will feed AI models faster, and the other is a company-wide critical pipeline that is currently a batch bottleneck.
Longer term, the goal is to shift Kuaishou's core data processing from batch to incremental computing as the default. The team is also exploring tighter integration between near real-time pipelines and AI models -- faster A/B test iteration, real-time signal collection, shorter feedback loops.